 蓝海创意云范导
蓝海创意云范导
首先我们要讨论下什么是GPU Cache工作流,以及它对我们渲染环节有怎么样的益处。
传统流程的场景模型、动画模型都是reference到渲染scene中的,这意味着加载场景的速度会非常慢,而且场景中动画模型可能存在较多绑定组件,在调试灯光的时候资产笨重,降低工作效率,随着制作水准的不断提高,场景会越来越复杂,加载和调试场景会成为一场噩梦。
GPU Cache工作流是只加载生成好的缓存文件比如Alembic缓存到内存中,会稍微增加内存资源的占用,但是极大的提高了场景加载的速度,其渲染速度也明显提升,同时场景非常干净,没有多余的节点,调试的时候也非常便捷。
那么接下来我们看看Maya中是如何进行GPU Cache工作流的。
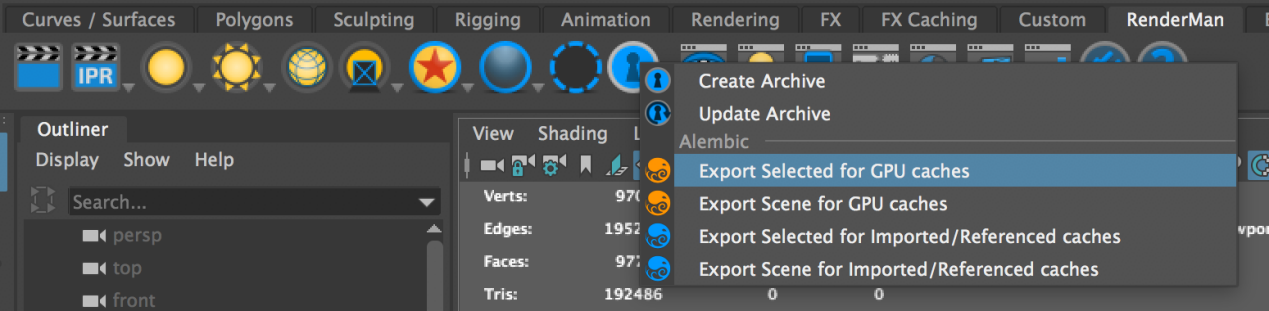
首先将几何体导出GPU Cache,我这里从官网下载了一个已经Group好的Rolling Teapot文件,是Alembic格式的。
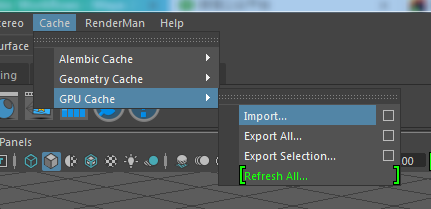
在Cache>GPU Cache>Import...中导入.abc缓存文件到场景中。
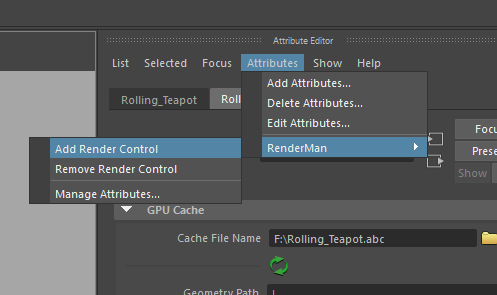
你去渲染它,发现是没有结果的,这个时候我们给节点Attributes添加Add Render Controls,如图所示。
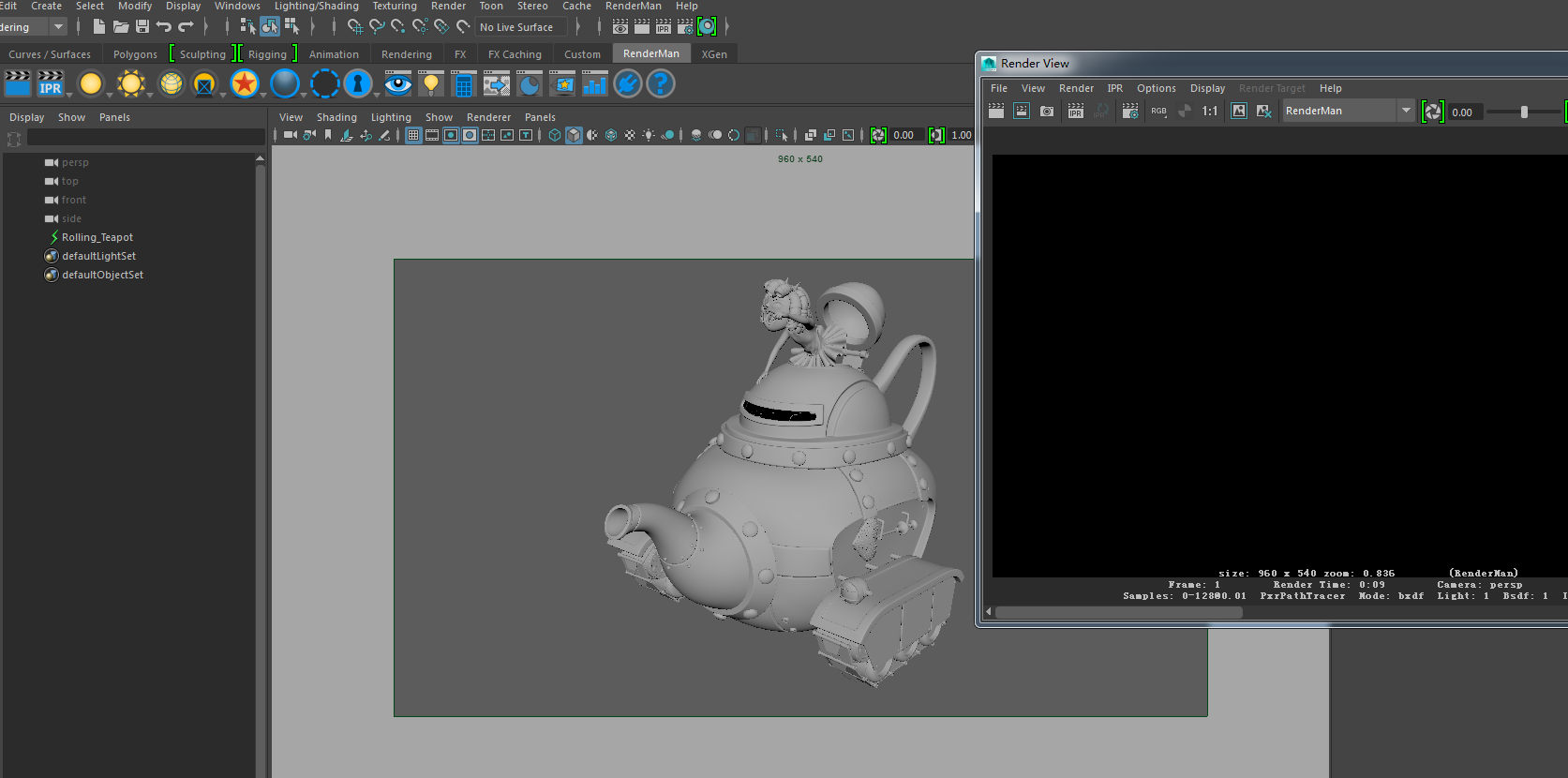
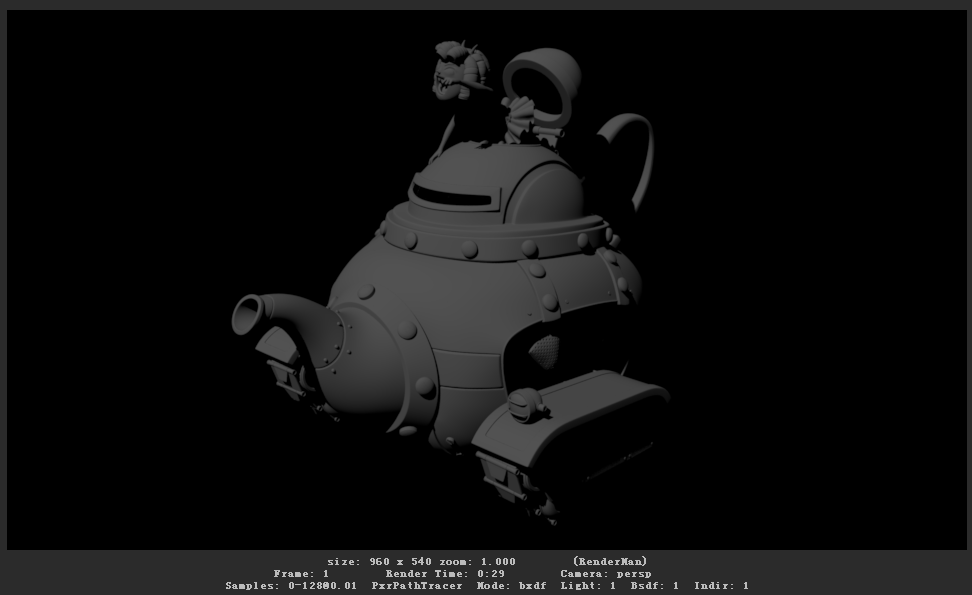
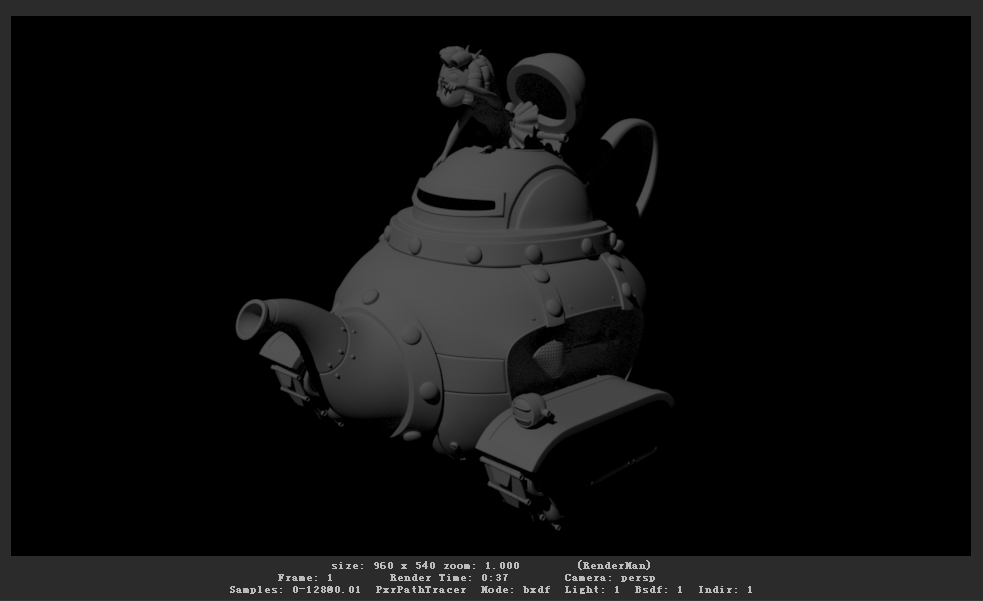
接下来我们测试下渲染的时间,我这边显示的渲染时间是29秒,现在我们删掉该节点,以导入Alembic缓存的方式再次测试下渲染速度,这次的渲染时间是37秒。我们发现,以GPU Cache的方式加载场景中的几何体,可以减少渲染时间,提高渲染速度,那么在复杂的大场景中,GPU Cache的加载方式使得场景在浏览的时候也不会太卡,具体情况大家可以实际测试一下。(渲染结果如下图所示,摄像机没有变化。)
导入场景中的GPU Cache只有一个节点,确实让场景变得很干净,但是这要怎么管理模型呢?RenderMan很贴心为我们准备了Inspect Alembic工具,我们可以很方便的去检索模型的层级。
初次加载GPU Cache的时候,我们点击Read archive contents,程序会parse(解析)这个模型,比较复杂的模型可能要解析一段时间,但是解析过后的parsed data会保存起来,下次打开的时候就不会re-parse了。
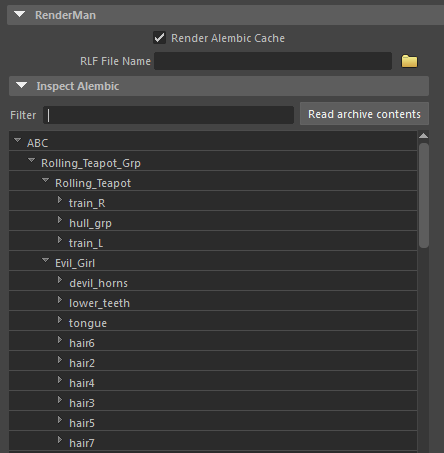
我们来学几个Filter的命令:
*:这个字符替代所有的字符
?:这个字符替代任意一个character字符
[seq]:按照顺序替代一个character字符
[!seq]:不按照顺序替代所有character字符
比如:“?hair”=找到一个名为character字符后的hair字符,如果你的场景很复杂,那么命名同样也会很复杂,有替代的字符可以快速检索模型。
实现了渲染,我们还希望添加材质,这点我们怎么处理呢?
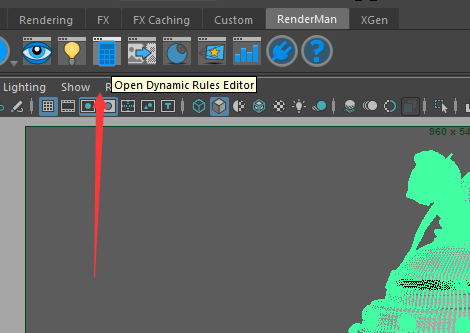
我们打开Dynamic Rules Editor,并把它拖到最下面合并起来,否则无法创建连接。
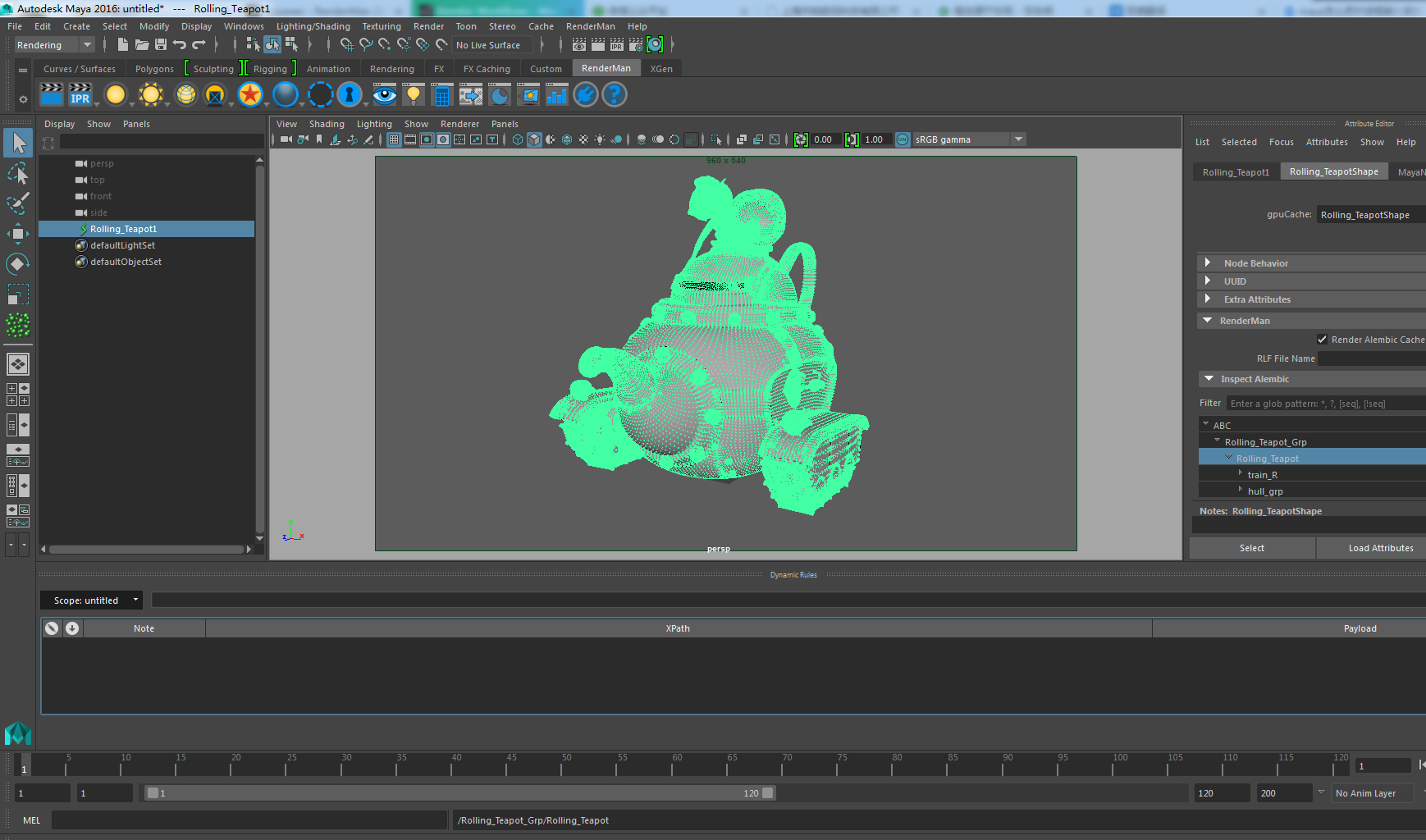
单击Rolling_Teapot节点选中它,再单击Add rule按钮。
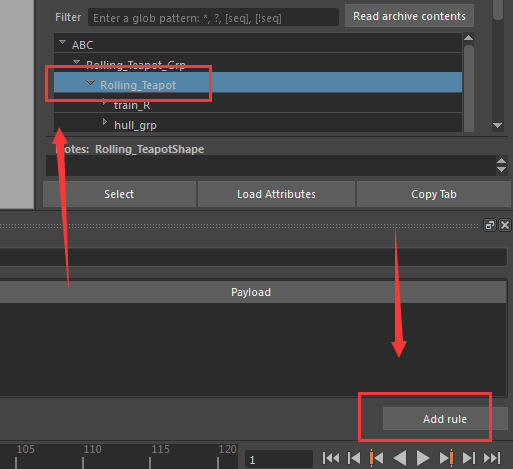
双击XPath,然后用鼠标中键把Rolling_Teapot拖过来进行赋值,并修改成如下格式。
//Rolling_Teapot_Grp/Rolling_Teapot//*
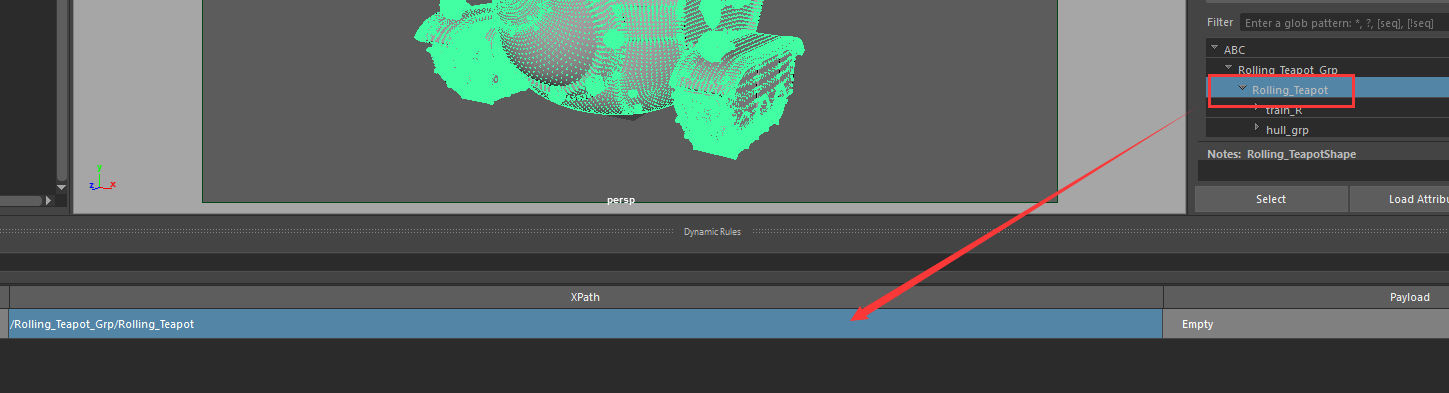
单击Payload,我们就可以选择一个已经存在的材质,并赋给模型了。
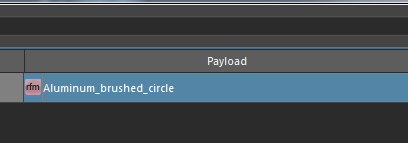
我们来学一个简单表达式:
//Rolling_Teapot_Grp/Rolling_Teapot//*[contains(name(), 'rivet') or contains(name(), 'screw')]//*
[]表示Group中的内容,contains(name(),‘XXXX’)表示找到名为XXXX的节点,这个表达式非常的简单,对于一个命名比如turret_ring_rivet2,如果Dynamic Rules Editor中有两个表达式,上面是匹配ring的,下面是匹配rivet的。那么根据匹配的规则,当匹配到ring的时候,匹配就会停止,下面的匹配也不会超越ring的层级。所以,我们必须把匹配rivet的表达式放在最上面,也就是说,越是上面的表达式,越接近底层级。
其他表达式内容:
//Rolling_Teapot//*[contains(name(),'rivet') and not(contains(name(), 'screw'))]//*
//Rolling_Teapot//*[starts-with(name(),'ring_')]//*
//Rolling_Teapot//*//train_L//* | //Rolling_Teapot//*//train_R//*

接下来我们简单介绍下VDB的内容,我们打开Maya,切换到FX模块。
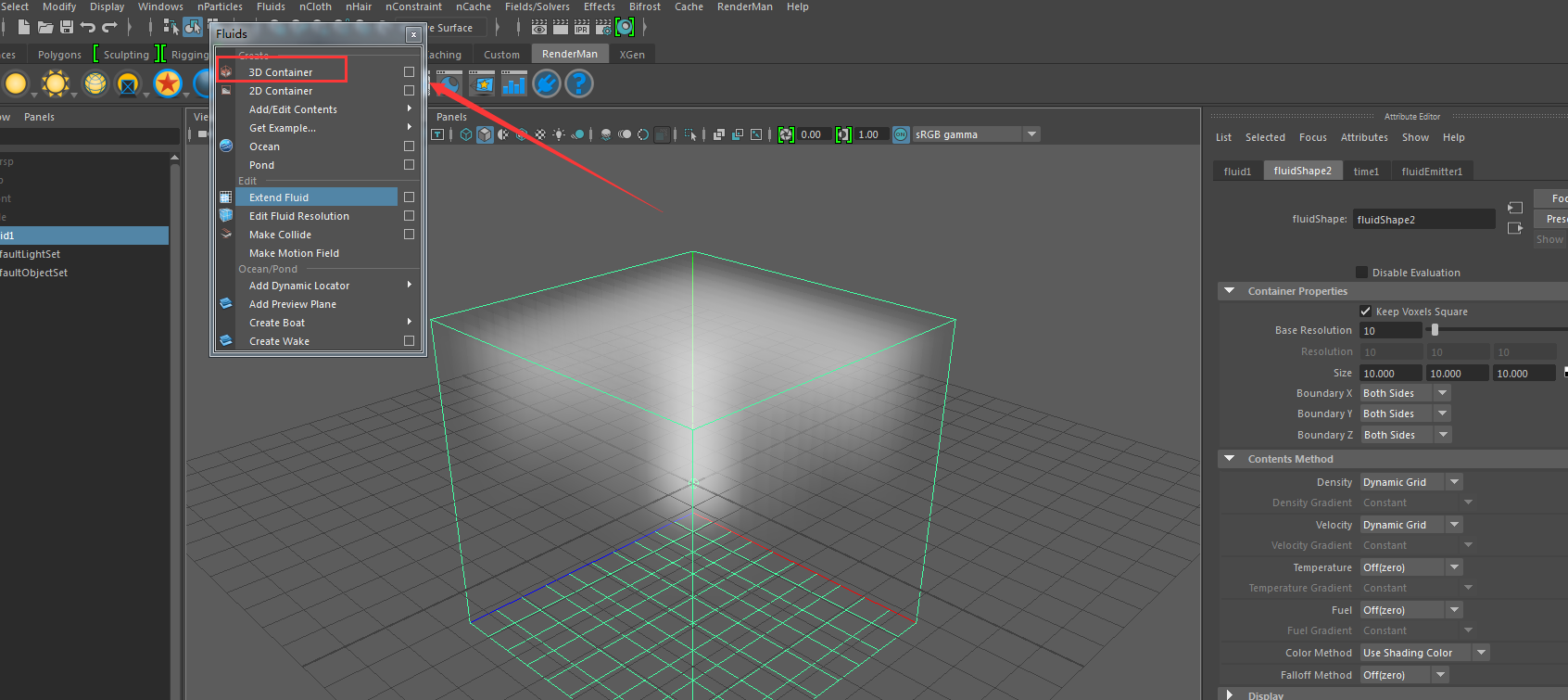
Fluids菜单下,我们用3D Container工具创建一个fluid节点,这个是Maya自带的Volume Description,Volume是几何体中用来描述流体、气体等非均匀介质的一种模型,显然这个和多边形的描述是不一样的,Maya自带的Volume Description已经含有材质,RenderMan可以直接渲染。
但是在实际项目中,使用最多的还是openVDB描述,VDB的英文全称是: Volumetric, Dynamic grid that shares several characteristics with B+trees,是一种具有多种B+tree(一种数据结构)结构的混合在一起的动态的、体积的网格,详细描述可查找论文:
VDB: High-Resolution Sparse Volumes with Dynamic Topology
KEN MUSETH
DreamWorks Animation
这是梦工厂对于CG界最大的技术贡献之一。
那么在RenderMan中,我们怎么加载openVDB呢?
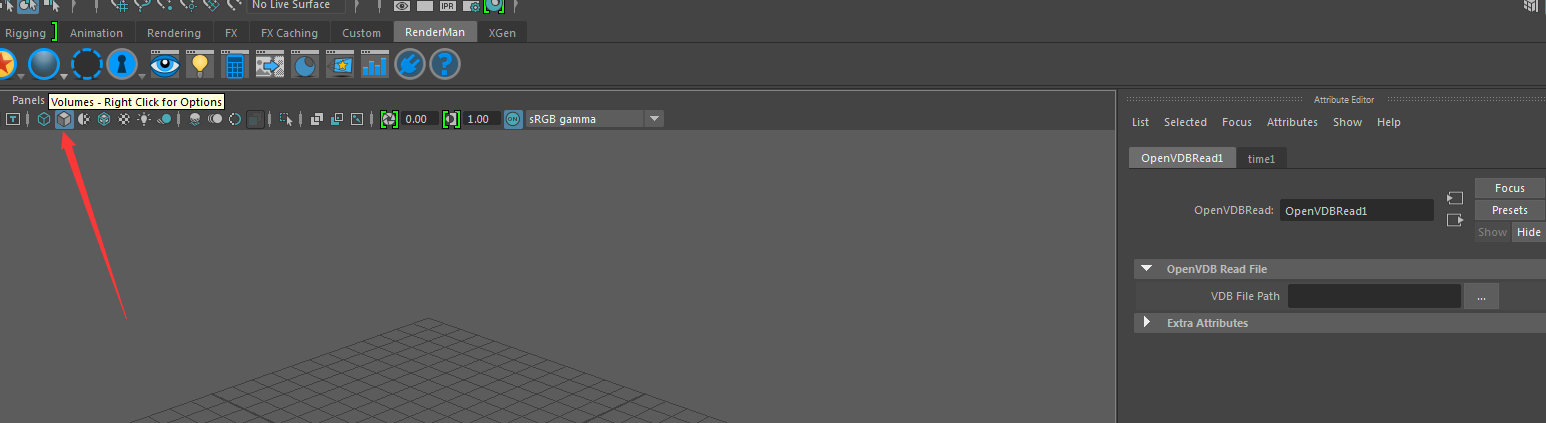
点击RenderMan的Volumes,我们就可以得到一个让我们读取VDB文件的接口。
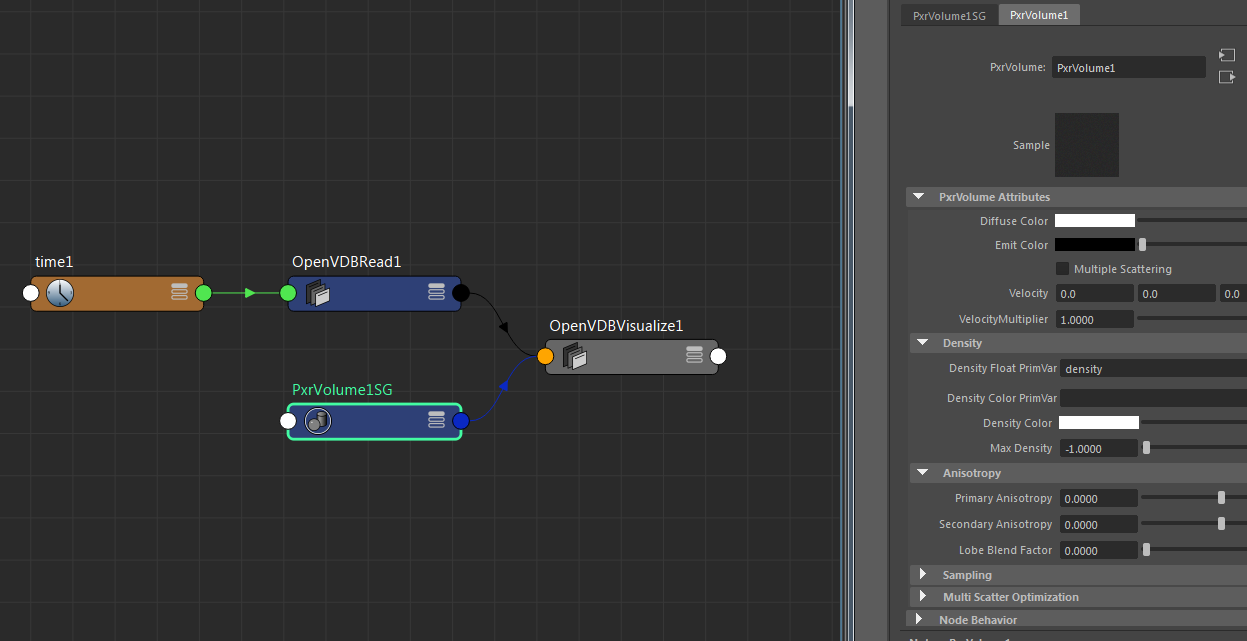
我们同样可以看到,RenderMan已经为我们连接好shading Group,包含PxrVolum


创意云渲染微信号

创意云官方微博

创意云官方微信
